

type
status
date
slug
summary
tags
category
icon
password
2017年,Google的一篇《Attention All You Need》论文,给AI领域带来全新的算法框架,以GPT为代表的生成式预训练大模型把AI带向了新的高度。
经过两年的发展,2025年的当下,将是大模型进入企业应用环节的重要时间点。而大模型进入企业应用环节不可避免的需要进行领域化,也就是将通用大模型通过微调,训练成适配特定领域的专业大模型。
而想要微调出业务满意的大模型,就需要对大模型的底层模型框架Transfermor有深刻的理解,这些深刻的理解,能够在面对复杂的业务环境下,帮助高效的微调大模型。
读者收益:
人工智能的本质是什么?
神经网络的核心构成是什么?
神经网络是如何应用在NLP和CV两大任务领域的?
自注意力机制是如何构造出著名的Transfermor框架的?
注:本文不涉及复杂的数据公式推导,只用通俗的语言一步一步拆解复杂的大模型。
从数学和工程角度理解人工智能的本质
AI是一个保罗万象且在不断泛用的概念,不管是资本的炒作,还是媒体宣传,大众对这个概念已经很熟悉了,但其实很难一下子抓住AI的核心。
其实如果从数学角度理解的话,这个内核一句话就能概括:基于数学工具,找到一个从数据到目标的一个函数,更精简的说法是AI即函数。目前火热的LLM(大规模语言模型),其实就是从自然语言中构建了一个到现实智能之间的函数关系。
这里的数学工具主要是指的微积分(重点是sigmoid和tan函数)、线性代数(主要是矩阵运算)和概率论。这个函数有两个重要的部分:从数据集中学习到的特征,和这些特征对目标的贡献值(权重)。
AI领域,传统的机器学习中,参与训练的参数(特征)一般在几十到百之间,对数据量级和算力资源要求相对比较小,而进入到深度学习中,模型参数入门级都在亿级别之上,比如Open AI 的o1、DeepSeek R1,参数规模都在千亿级以上。
理论上是一个函数,那实现层面的算法工程上怎么找到这个函数呢?这就要谈到算法工程的经典步骤:数据收集、预处理、特征工程、训练、评估与部署。最近两年,大家听到的各种各样的大模型,都在基于这条“模型生产工作流”训练出来的。模型的算法框架在不断的迭代更新,各种概念更是层出不穷,牢记好这条生产线,在算法世界的学习研究中,就不会迷乱。
为了深入理解Transfermor,接下来我们从基础的神经网络开始。
神经网络里面的核心概念与底层原理
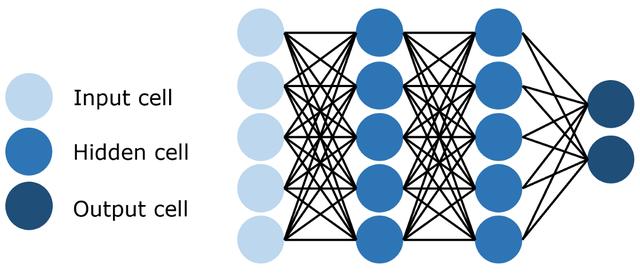
图中的一个个小圆点就是神经元,众多的神经元和连接一起构成了神经网络,包含了输入层、隐藏层、输出层。更多的隐藏层就构成了深度神经网络。
这是一个模拟人脑的人工神经网络,这里重点拆解下这几个核心概念。
神经元:这是一个神经网络模型最核心的计算单元,其来源于数学模型是M-P神经元模型,是神经网络中最核心的计算单元,包含了输入、权重、偏执、阈值、激活函数。
激活函数:现实世界的规律并非都是规律的,激活函数的引入可以让神经元学习到非线性特征,从而让神经网络可以逼近任何非线性函数,常见的激活函数有sigmoid、ReLU、Tanh等。
- Sigmoid:把数字压到0到1之间,像个概率值。
- ReLU:负数变0,正数不变,简单粗暴但很有效。
- Tanh:把数字压到-1到1之间,像个平衡器。
损失函数:用来评估模型预测和真实结果之间的差距。任务类型不同选用的损失函数也不一样,回归问题用均方误差、分类问题使用交叉熵。
以上的神经网络,用通俗的语言表达就是,在精心准备的数据集上,通过精心设计的一个神经网络结构,并根据损失函数的反馈,不断地迭代学习到一个函数,这个函数就是所谓得的模型。
基于神经网络模型发展出来的经典深度学习算法有:CNN、RNN(LSTM、GRU)、GNN(图神经网络)、GAN(生成对抗网络)、Transfermor、DBN(深度信念网络)。这里重点介绍下经典两种神经网络结构CNN、RNN。
神经网络经典算法:CNN与RNN
CV领域的CNN(Convolutional Neural Networks)
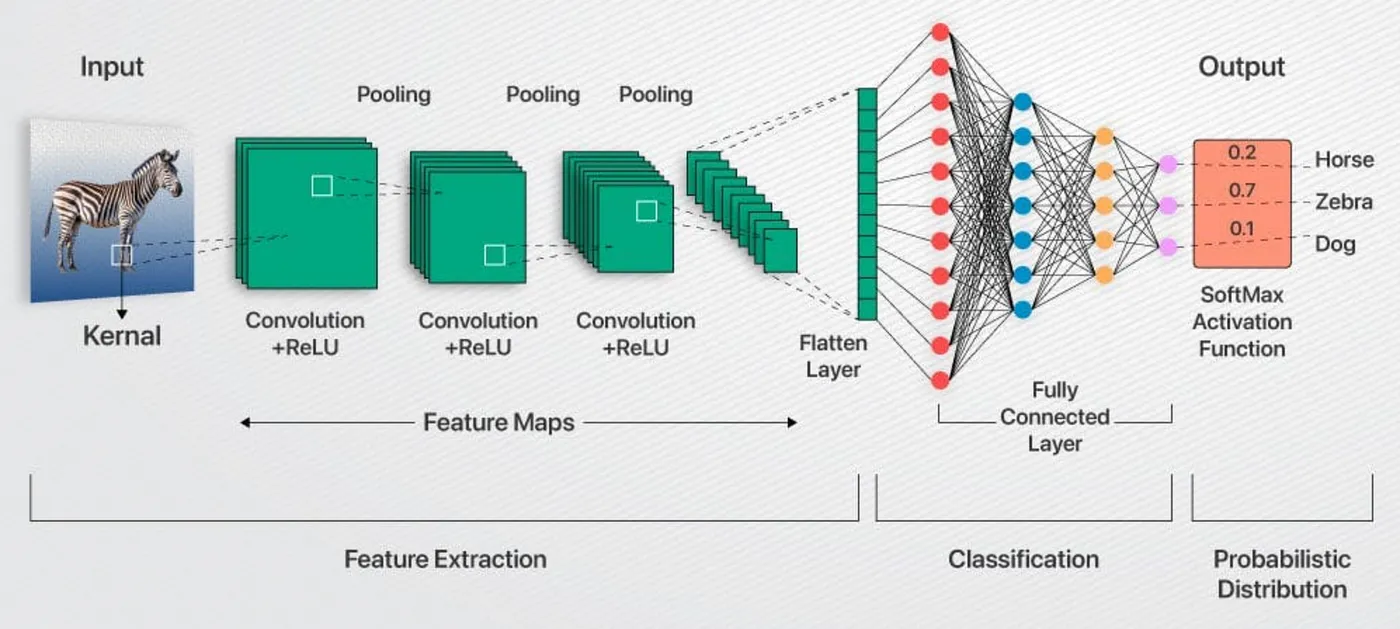
一句话说明CNN的核心思想:从局部到整体,层层提炼特征。
就像人眼看一张图片的时候,一般是先看局部细节,如线条、颜色。然后将这些细节拼出来认出整体。CNN也是一样,它通过一种叫“卷积”的操作,模仿人眼“扫视”图片,找出图片里的局部特征。这一步对应到算法生产工作流中的特征工程一步。
CNN的训练流程大致是:输入一张图片,使用卷积核扫描出图片的特征,通过池化技术实现降维,保留图片关键信息。经过多轮的卷积和池化,挖掘出更高的特征。最后通过全连接层把所有特征综合起来分析判断,最终输出的是各种情况的概率。这里面涉及到几个核心的概念:
卷积层:简单理解就是使用卷积核提取特征。卷积核是一个小方块(比如3x3),它在图片上滑动,每次只看一小块区域,算出这个区域的特征。卷积核扫完整张图片后,会生成一张新图,叫“特征图”。这张图记录了图片里的局部特征,比如边缘、角落。CNN有多个不同的卷积核,每个核擅长找不同的东西:一个找横线,一个找竖线,一个找圆形等等。这样就能挖出更多特征。
池化层:池化就像CNN的“精简大师”(降维)。它把特征图的信息压缩一下,保留重要的,丢掉不重要的。怎么压缩?比如“最大池化”:在一个2x2的小区域里,只留下最大的那个值,代表这个区域最明显的特征。池化让CNN更关注整体特征,减少计算量,还能避免“死记硬背”(过拟合)。
激活函数:CNN常用的是ReLU,给学习加点“灵活性”(非线性),使得模型能够学习到复杂的模式。
全连接层:做决策的一层。将卷积或者池化层的特征映射到一个一维向量。全连接就像搭了个普通神经网络,把所有特征连起来,综合判断图片里是什么。输出结果最后用一个函数(比如softmax),给出分类结果,比如“90%是猫,10%是狗”。
训练的过程中,为了防止过拟合,采用随机丢弃一部分神经元,也就是dropout技术。
之所以CNN技术这么强,主要是因为卷积的存在使得每次处理的时候,只需要关注局部且卷积核可以重复使用,这样就让参数量不至于太多。提取的特征是与物体在图片上的具体位置无关,这就让CNN更加精准的识别出物体。
NLP领域的RNN(Recurrent Neural Networks)
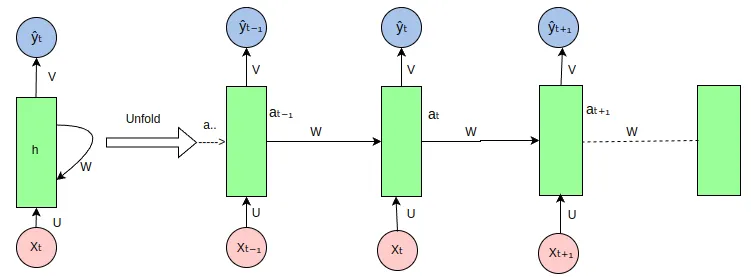
RNN主要应用于具有序列特征的数据,比如股票数据、语言数据、视频数据等。RNN中主要有三种形态:标准RNN、长短期记忆(LSTM)、GRU(门控循环单元)。
标准RNN
标准RNN结构是,每次都把上一次记忆的内容和当前的输入token,一起送进RNN训练结构中,序列数据之间顺序关系就通过上一次记忆内容来表示。就这样循环往复,直到数据全部训练完。这么一种结构,就非常适用于处理文本分类、翻译等任务。
但是有一点,RNN有两个比较棘手的问题:梯度消失和梯度爆炸。
梯度消失在训练RNN时,随着序列长度的增加,反向传播中的梯度会逐渐变小(趋近于0),这使得模型难以学习到序列中较早时间步的信息。这种“健忘症”导致RNN无法捕捉长期依赖关系。
梯度爆炸与梯度消失相反,梯度有时会变得过大,导致模型参数更新不稳定,训练过程难以收敛。
简单神经网在学习过程中, RNN学习到误差,在反向传播中,如果这个误差小于1,则在不断的反向传播中,这个误差会逐渐趋近于0,也就是梯度消失。如果这个误差大于1,则在不断的反向传播中,这个误差会逐渐趋向无穷大,也就是梯度爆炸。
为了解决以上问题,在简答RNN的基础上新增了三个控制器:输入控制、记忆控制、输出控制。这就形成了新的模型LSTM(长短期记忆)。LSTM中引入了sigmoid和tanh函数。
为解决梯度消失推出LSTM
LSTM是为了解决RNN的梯度消失问题而设计的,特别适用于需要记住较长序列信息的情况。它通过特殊的结构(三个门)增强了模型对长期依赖关系的建模能力。
- 遗忘门:决定丢弃哪些过时的信息。
- 输入门:决定添加哪些新的信息到记忆中。
- 输出门:决定当前时间步输出哪些信息。
此外,LSTM还有一个“细胞状态”,相当于长期记忆的载体,可以在整个序列中传递信息,从而保留重要信息。
GRU:LSTM的简化版
GRU主要保留LSTM解决梯度消失问题的能力,同时减少计算复杂度,提高训练效率。
- 更新门:控制保留多少旧信息并加入多少新信息。
- 重置门:决定忘掉哪些旧信息并如何与新信息结合。
通过更简单的结构,GRU依然能有效捕捉序列中的依赖关系
总结来说,LSTM和GRU的出现是为了解决标准RNN在处理长序列时的梯度消失和梯度爆炸问题,从而更好地捕捉长期依赖关系。LSTM通过复杂的门控机制和细胞状态实现了强大的记忆能力,但缺点是计算复杂、参数多、难以并行化。GRU则简化了LSTM结构,提高了计算效率,但表达能力和对极长序列的处理能力稍逊一筹。生产环境下,选择LSTM还是GRU,通常取决于具体的任务需求(如序列长度、计算资源)和数据规模。
随着2017年,Google发表的一篇论文《Attention is All You Need》,开启的神经网络发展的全新时代。 这里我们重点讨论下开启AIGC时代的底层算法框架:Transformer。
从自注意机制到Transfermor架构的构建分析
提到Transfermor,就绕不过大名鼎鼎的自注意力机制。
自注意力机制 Self-Attention Mechanism
这是一种在深度学习中广泛应用的机制,特别是在处理序列数据时。本质是一种捕捉序列中每个元素与其他元素间的依赖关系,即上线文关系。它允许模型在处理一个序列中的某个元素时,能够根据该元素与其他元素的相关性,动态地“关注”到序列中其他部分的重要性。这种机制在Transformer架构中尤为关键,是自然语言处理(NLP)领域的一个核心创新。
自注意力机制的核心思想(工作原理):通过计算序列中每个元素与其他元素的相似度,来决定每个元素的上下文表示。具体步骤如下:
- 输入表示:假设有一个输入序列(比如一个句子),每个词被表示为一个向量(通常通过词嵌入生成)。
- 计算相似度:对于序列中的每个元素,模型计算它与序列中所有其他元素的“相似度”。这种相似度通常通过向量之间的点积(dot product)计算,点积越大,表示两个元素越相关。
- 生成注意力权重:将相似度通过softmax函数转换为权重,这些权重之和为1,表示每个元素对当前元素的“关注”程度。
- 加权求和:使用这些权重对序列中所有元素的表示进行加权求和,得到一个新的表示,这个表示融合了序列中其他元素的信息。
自注意力机会再算法工程上是如何实现的?
想象一下,你在参加一个讨论会,每个人都有自己的问题和信息。Transformer 中的 Q、K、V 就类似于这种场景中的三个角色:
- Query(查询):相当于你在讨论会中提出的问题,你希望得到什么信息。例如:“我现在需要知道A信息。”
- Key(键):相当于每个人的“名片”或者“标签”,它描述了他们所擅长或掌握的信息类别。比如,有人名片上写着“擅长A”,有人写着“擅长B”。
- Value(值):相当于每个人真正提供的内容。当你的问题(Query)与某个人的标签(Key)匹配得很好时,他就会把自己掌握的内容(Value)提供给你。
在 Transformer 中,每个词在句子里都会被转化成这三个向量。当模型想要理解(语义关系)一个词的上下文时,它会经过如下操作:
- 用这个词的 Query 去和所有其他词的 Key 进行比较(计算相似度),找到最相关的信息。
- 按照这些相似度给相关词的 Value 赋予不同的权重(weight)。
- 把这些加权后的 Value 聚合起来,生成对当前词的新的理解。这样,模型就能“关注”到与当前词最相关的信息,从而捕捉到整个句子的语义关系。
一个注意力头被用来挖掘上下文中的一种特征,而一段序列中,文本会有很多特征,为了理解句子的多个语义,就需要多个注意力头。
多头自注意力
在Transformer中,自注意力机制被扩展为多头自注意力(Multi-Head Self-Attention),这种做法的优点是充分利用自注意力间的并行处理能力,且对序列中的任意位置间的关系都能直接捕捉,无论它们相距多远。具体做法是:
- 将输入分成多个子空间,分别计算注意力。
- 每个“头”关注不同的特征或模式。
- 最后将所有头的输出拼接起来,增强模型捕捉序列丰富信息的能力。
Transformer架构
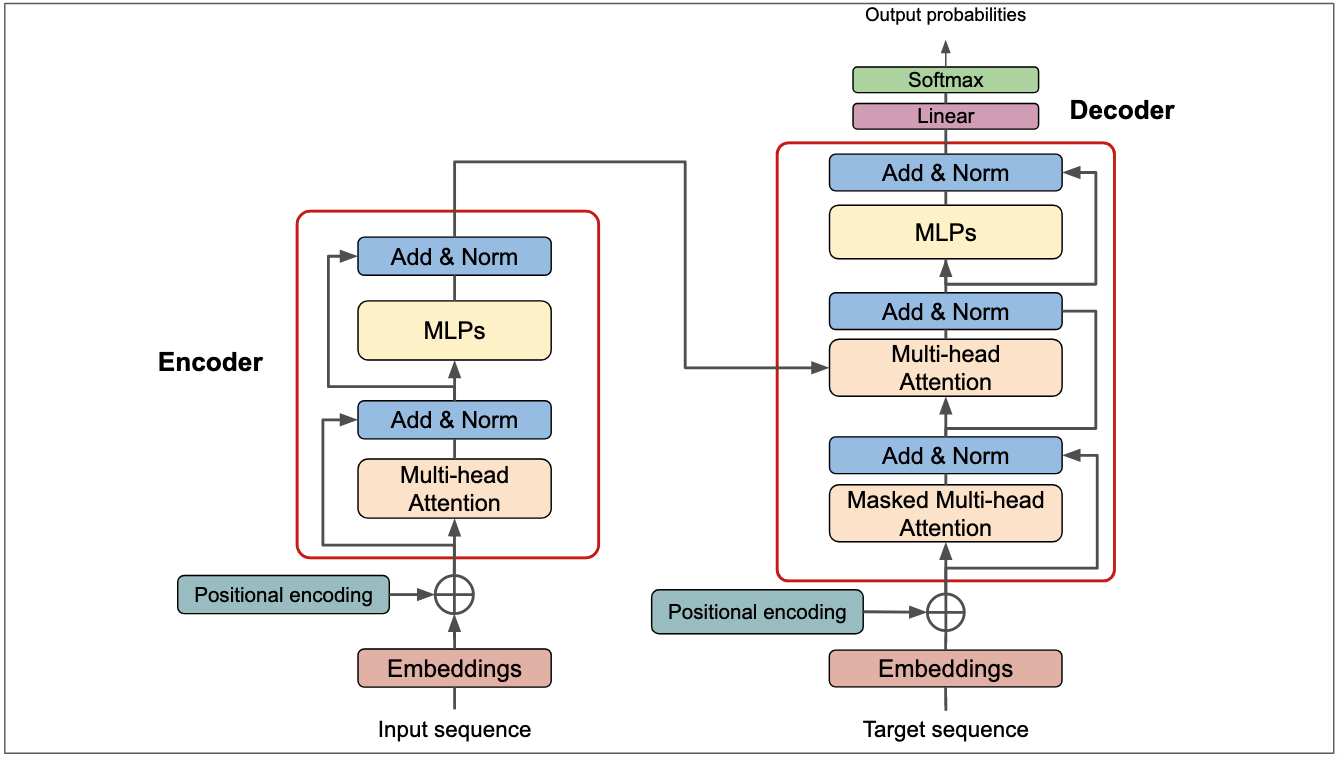
可以说,Transformer架构是自然语言处理领域的里程碑模型,完全基于自注意力机制,摒弃了传统的RNN和CNN结构。
用通俗语言概述Transformer的话就是,通过多注意力机制捕捉语言序列中的语义(上下文)信息,并把语义信息追加到特征中,并最终找到那个函数关系。从图上可以看出,Transformer架构主要分为了编码器和解码器两个部分,这两个编解码都源自自注意力头。用简单的话来总结Transformer,这里我们讨论几个关键的技术点:
编码器(Encoder)将输入序列转换为一系列捕捉语义信息的表示。编码器通常由N个相同的层堆叠而成(原始Transformer中N=6)。每个编码器层包含以下子层:
- 多头自注意力机制(Multi-Head Self-Attention):捕捉输入序列内部的依赖关系。
- 前馈神经网络(Feed-Forward Neural Network, FFN):对每个位置的表示进行独立的非线性变换。MLP 是一个更宽泛的概念,指的是由多层全连接网络构成的模型,Transformer中的FFN特指2层的MLP。Attention整合了Token的上下文信息,FFN则是在这个基础上,更提取更生层次的特征,这些特征能够让模型更加精准的理解和表达语言的含义。
- 附加组件:
- 残差连接(Residual Connections):每个子层后,将输入与输出相加,帮助信息流动。
- 层归一化(Layer Normalization):在残差连接后归一化表示,稳定训练过程。
解码器(Decoder)用来根据编码器的输出和已生成的序列,逐步生成目标序列。同样由N个相同的层堆叠而成(N=6)。每个解码器层包含以下子层:
- 掩码多头自注意力机制(Masked Multi-Head Self-Attention):与编码器的自注意力类似,但使用掩码(masking)确保只关注当前生成位置之前的位置,保持自回归特性。
- 编码器-解码器注意力机制(Encoder-Decoder Attention):使解码器关注编码器的输出,将输入序列信息融入生成过程。
- 前馈神经网络(Feed-Forward Neural Network):与编码器中的FFN相同。
- 附加组件:同样包含残差连接和层归一化。
其他关键组件还有将输入的词或token转换为向量表示的嵌入层(Embedding Layer),在解码器最后,通过线性层和softmax函数将输出转换为目标序列的概率分布的输出层。
Transformer处理的数据都是向量,也就是要经过embeding处理。通过编码将Token变成一个独热码, 然后进行降维(或者理解为抽象),这个过程就是embeding(或者称嵌入)。
可能有些朋友会觉得以上的技术点会有些难度,这里在给到一个理解Transformer架构重要工具:潜空间(Latent Space)。借用这个概念可以让大家忽略掉数学公式和晦涩的技术点。解释如下:Transformer架构中,输入内容经过Embeding之后,相当与把内容投射到一个高维空间(即潜空间),在这个潜空间中,通过多头注意力和位置编码技术,可以拆解出输入内容的语法、语义、语序、关系等核心信息,最后通过解码从潜在空间中提取信息,逐步生成目标序列。
可以说Transformer的出现不仅推动了NLP的发展(如BERT、GPT等模型),还影响了计算机视觉等领域,成为现代深度学习的重要基础。
Transfermor模型框架带火了生成式人工智能的发展,NLP领域的发展,也逐渐由RNN转向基于注意力机制实现是Transformer。而在CV(计算机视觉)领域也由CNN转向基于注意力机制实现的Diffusion。
最后
作者尝试用一句话来概述Transformer架构:通过自注意力机制,捕捉到序列数据中的上线文信息,通过FFN来更深层次的加工这些信息,最后通过并行且多层的Attention和FFN,使得模型能够捕捉到足够的语义、上下文信息,去做出最终的预测。之后根据损失函数(预测结果和真实结果的差异),利用BP(反向传播)计算每个参数的梯度(即每个参数对损失的贡献度),最后根据梯度更新模型的权重,经过不断地调整和优化,使得大模型的预测准确性更高。
最后回顾下本文的大致逻辑:本文首先通过数学和工程的视角,讨论了算法模型函数本质。接着讨论了”挖掘“这个函数的一种模型技术:神经网络(Neutral Network),并介绍了基于NN发展出来两个经典算法:CNN、RNN。最后重点讨论了如何基于神经网络,结合自注意力机制的全新思想,设计出大名鼎鼎的全新算法框架:Transformer。
下一章我们将讨论基于Transformer发展起来的通用LLM(Large Language Model),是如何被一步步训练出来的?欢迎关注。
相关内容参考:
‣
‣
‣
‣
‣
‣(MLP)
- Author:Taylor
- URL:https://taylorai.top/article/1c82186a-d85d-8009-bbc7-e419694a5b02
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts




